
2021年3月25日に放送されたGoogle検索オフィスアワーのまとめです。
ブログ記事
2021年2月25日のGoogle検索オフィスアワー以降のブログ記事です。
- Korean Blog: How CLS optimizations increased Yahoo! JAPAN News’s page views per session by 15%
- Korean Blog: How Wix improved website performance by evolving their infrastructure
- New for education sites:Practice problems and Math solver structured data
- Clarifications about the SharedArrayBuffer object message
- New resources for video SEO
- Providing better product information for shoppers
SharedArrayBufferに関する情報
先日Google Search Console経由で送ったメッセージの意味が分からないというフィードバックを頂いたので、少し丁寧に書いたものをGoogle Search Centralブログに載せてもらいました。多分後で日本語版も。
Clarifications about the SharedArrayBuffer object message https://t.co/2LJKnlRhQA— Eiji Kitamura / えーじ (@agektmr) March 20, 2021
- Chrome 91 より SharedArrayBuffer の利用に制限が付きます
- Making your website “cross-origin isolated” using COOP and COEP
- SharedArrayBuffer オブジェクトに関するメッセージについての説明
お知らせ
Google検索セントラル ヘルプコミュニティで高野さん (@takano_seo) がゴールドプロダクトエキスパートになりました!
【ご報告】このたび、Google 検索セントラル(旧:ウェブマスター フォーラム)のゴールド エキスパートになりました。引き続き困ってる方の助けになれるよう精進します!
なお SEO すごく詳しいとかではなく、コミュニティへの貢献によるものなので、業界の有識者の皆様はくれぐれも優しくし(文字数
— t̶a̶k̶a̶n̶o̶ (@takano_seo) March 8, 2021
Q&A
インデックスが削除され続けている
【質問】
今年に入ってからサイトのURLがインデックスから削除され続けている。
原因と考えられていた大量のカバレッジエラーを出していた古いCGIの削除、.htaccessのリダイレクトの修正などを行った。あとはrobots.txt取得の合格率をホスティング事業者に確認したところ、設定に問題は見られないと言われ、お手上げ状態になっている。
具体的には以下のものがインデックスから削除されている。
- 重複による除外
- クロール済み – インデックス未登録
【回答】
頂いたURLを確認したところ、MFI 移行済みのサイトに対してモバイルのGooglebotがクロールできていない状態だった。その結果、インデックスされているURLが削除されていた。サーバの設定を見直してください。
Seach Consoleのクロールの統計情報を確認すると、クロールの状況を把握できるので、修正の際の参考になるのでは。
インデックス登録はあるが site: 検索に出ない
【質問】
URL検査ツールでインデックス登録されているが、site:検索で表示されない場合、サイトに問題があるのか?
【回答】
site:検索はインデックスされているかを外部から確認するには有効だが、それ以上の使い方はあまり適切ではない。
URLを頂いていないので細かい点はわからないが、インデックスを確認したいのであれば、カバレッジレポートやURL検査ツールを使ってください。
カバレッジのエラー・除外が急増した
【質問】
2021年1月中旬よりカバレッジエラー (除外) が急増した。
サイトを改修していないのだが、クローラの仕様が変わったのか?
クロール効率や低品質サイトと認識されるリスクもあるので、改善を検討している。
【回答】
頂いたURLを確認した上でコメントする。
Googleの仕様が変わったかということは置いておいて、URLの構造に改善の余地があるのでは。
何かのタイミングでパラメータがどんどん付与されるような仕様になっている。つまり重複するページが増えている。その結果、除外が急増しているのでは。
URLの正規化をしてください。URLパラメータツールを使うか、canonicalを使うといいのでは。
ファセットナビゲーションの記事にベストプラクティスが載っているのでご覧ください。
日英多言語サイトでカバレッジエラーが多い
【質問】
Search Consoleでほとんどのページがカバレッジエラーとなっており、「送信された URL に noindex タグが追加されています」と表示される。他には数ページが「ソフト404エラー」と表示される。
以下のことがわかっている。
- ソースにnoindexはなく、robots.txtは存在しない
- インデックス登録をしても失敗する
- ライブテストから登録すると、拒否の理由が「ソフト404」
同じサイトのディレクトリ下層に英語サイトがあり、社名を検索するとなぜか英語サイトが検索結果に表示される。クリックすると。日本語トップページが開く。この辺り理由も教えて欲しい。
【回答】
頂いたURLを確認した。
他言語サイトの構成だったので、その辺りが影響しているのでは。
日本語と英語のページが1対1ではなく、英訳されていないページもあった。日本語しかないページを、端末の言語を英語に設定して表示すると、トップページにリダイレクトされていた。
クローラもリダイレクトされるので、英訳されていないページがインデックスされなかったのでは。ソフト404になっているのは、まさにその症状。
他言語サイトについては、Googleが推奨している仕様がドキュメントに記載されているので確認してください。
noindexタグが追加されていますに分類されたのは、実際にはnoindexが追加されていないのかもしれないが、インデックスする必要がないものが振り分けられている可能性があるので、確認してください。
最近リニューアルされているので、もしかしたら最後にクロールした時にnoindexが入っていた可能性も考えられる。
関係のないドメインからの重複コンテンツ
【質問】
URL検査ツールで「重複しています。送信された URL が正規 URL として選択されていません」と表示される。
「Google が選択した正規 URL」に異なるドメインが表示されているがなぜか?
【回答】
頂いたURLを確認した。
サイトがハッキングされて、コンテンツを埋め込んだサイトが正規URLとして選ばれてしまった。
Googleが選択した正規URL (異なるドメインのサイト) をハッキングされたサイトとして、スパムレポートを送信してください。
ハッキングに関して、高野さんの記事がわかりやすくまとまっているのでご覧ください。
重複コンテンツと判断される基準
【質問】
サイトAに記事を寄稿している。いい記事なので、自分のサイトBにも掲載したい。
サイトAとBでは、それぞれ読者が異なる。
以下質問する。
①今回のケースでは、重複コンテンツとしてペナルティの対象になるのか?
②ペナルティにならなかったとしても、重複コンテンツが多くなるとサイトBの評価は下がるのか?
③サイトBに掲載するにあたり、何かいい方法があれば教えて欲しい。
【回答】
①重複コンテンツはペナルティの対象にならない。
②Googleがスパム対策にどのように対応しているかについて、たとえばどんな単位で、どのように判断しているかについては、手の内を明かすことになるのでお伝えできない。
正当な目的を持って重複コンテンツとなってしまい、サイト全体がほぼ重複でなかなか検索結果に表示されにくくなったことは、聞いたことがあるが、これはサイト全体が低評価になったというよりは、別のサイトのコンテンツが優先的に検索結果に選ばれていることが原因のケースが多い。
サイトの主な目的がアフィリエイトサイトや広告収入を得る場合は、少し話は変わってくる。同じページを量産しているケースでは、手動による対策や自動の対策になる可能性はある。ただし、通常の範囲で広告を貼っている場合に問題が出るという単純な話ではなく、一般的な範囲で広告があることで問題になることはない。
③canonicalタグを入れるのがよい。
金谷さんの個人的な意見としては、読者が違うというお話なので、引用のような形で解説するような記事を作成するという選択肢もあるのではとのこと。
外部メディアにサブディレクトリを貸すリスク
【質問】
SEO事業者より、「弊社のドメインのサブディレクトリを借りてメディアを運営したい」という提案をもらった。弊社なメディアの運営に関与しないが、メディアからの利益の一部が分配されるビジネスモデルの模様。
金融系メディアではこのような形態のサイトもあるようだが、ドメインを第三者に増すことは不適切だと考えており、Googleの見解を伺いたい。
ペナルティはなかったとしても、メディアの評価が落ちた場合、間接的に弊社サイトへの悪影響があるのかも教えて欲しい。
【回答】
サイトの情報もないので一般論としてお答えする。
Googleが、なぜアルゴリズムの改善が行っているのか説明する。
例えば、ユーザーのためにならないようなコンテンツが、不当に高い順位がついてしまうと、Googleはその状況が良くないと考えて、適切な順位になるように改善を行う。その逆もあり、不当に低い順位がついているものは、正しい順位になるようにしたい。
ユーザーにきちんと届けられるようにするためにアルゴリズムを調整している。
ご質問に書いてあるような施策でうまくいってしまっているケースもあり、不満をお持ちの方もいると思う。うまくいっているケースが目につくが、うまくいってないことも多く、相当なケースは抑えられていることが多い。
このような状況で、これだけ不快に感じている方がいる中で、このような施策を取ることのリスクは考えた方がいい。サイトやブランドとして、どうなのかという視点で考えると良いのでは。
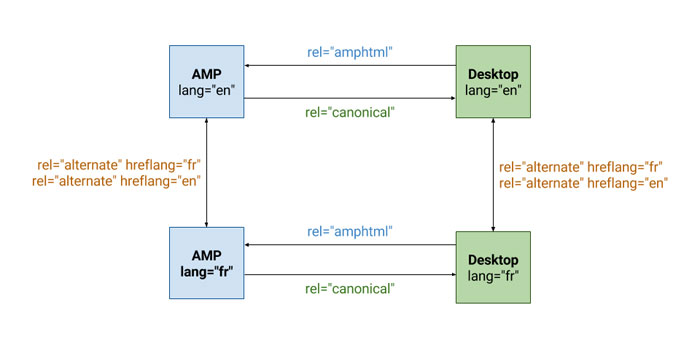
多言語サイトでの正規化を行う
【質問】
hreflangを設定している他言語サイトの正規化は、それぞれの言語バージョンのページは、自身の言語ページへcanonicalを設定すればいいのか?
もし、別々のURLの場合、自身の言語のデスクトップバージョンへcanonicalを向ければいいのか?
【回答】
hreflangでサイトを他言語するだけなら、canonicalを設定する必要はないが、何らかの理由で正規化したい場合、言語ページにcanonicalを行えばいい。
AMPのドキュメントにアノテーションについてわかりやすい図があるので、参考にしてくださいとのこと。
サイトマップの正規化は必要か
【質問】
sitemap.xmlの正規化は必要か?
Search ConsoleでURL検査を行うと、サイトマップに次のように表示される。
パラメータがついていても同じ内容が表示されているのだが、パラメータなしに正規化する必要はあるのか?
サイトマップ例
https://www.example.com/sitemap.xml/index.xml
https://www.example.com/sitemap.xml/index.xml?a=2
https://www.example.com/sitemap.xml/index.xml?a=testing
【回答】
特に何かする必要はないとのこと。
クロールの効率が悪いのであれば、robors.txtでクロールを制御すると良い。
正規 URL が正しく認識されない
【質問】
異なるコンテンツだが、「重複しています。送信された URL が正規 URL として選択されていません」と表示され、ユニークな情報を持つページがインデックスされずに困っている。
当サイトは、複数ページ構成の記事を配信することが多く、URLパラメータで記事を管理している。記事1ページは歴史的背景もありパラメータ名が異なる。
パラメータ名が異なることが原因と考え、URLパラメータツールを使い、「Googlbotが決定」から手動に変更した。1週間くらいは1ページ目も認識されるようになったが、その後2週間で元に戻ってしまった。
【回答】
頂いたURLを確認したが、ご質問の状況を確認できなかった。
記事が分かれているというのは、1ページ目が記事トップページ、2ページ目が記事の1ページ目、3ページ目が記事2ページ目というような構成だと思う。
1ページと2ページ目は同じコンテンツにしか見えなかったので、正直何が問題なのかわからなかった。状況を、もう少し詳しく質問してくださいとのこと。
正規化に関する公式ページの情報は最新か
【質問】
2013年に公開されたcanonicalの記事だが、内容は正しいのか?
上記URLに間違いの例として書かれている「間違い 1: 複数ページにまたがるコンテンツの 1 ページ目を rel=canonical のリンク先とする」ですが、会社のウェブサイトは、複数ページにまたがるコンテンツの1ページをrel=canonical のリンク先としています。
この記事を会社に伝えたが、2013年の記事は古くないかと言われて、自信を持って反論できない。
rel=canonical 属性に関する 5 つのよくある間違い
【回答】
ページネーションは廃止されているので、その部分は古くなっているが、全体的な方向性は有効。今回の「間違い 1: 複数ページにまたがるコンテンツの 1 ページ目を rel=canonical のリンク先とする」に関しては古くないのでご安心ください。
以下のページも合わせてご覧ください。
同じ正規化方法を使用するか異なる正規化方法を使用するかにかかわらず、複数の異なる URL を同じページの正規 URL として指定しないでください(たとえば、サイトマップで特定の URL を指定しているにもかかわらず、同じページに対し、rel=”canonical” を使って別の URL を指定するようなことはしないでください)。
検索アナリティクスの一部データ表示の基準
【質問】
Search Consoleの検索アナリティクスで、大きなサイトでキーワードやURLで絞り込むと、一部データしか表示されない。
「ランダムサンプリング」「何らの基準で切り捨て」のどちらになるのでしょうか?
サンプリングや切り捨てについては、「指定した期間での合算での処理」「一日単位で処理したものを合算のどちらなのか?
【回答】
検索アナリティクスではなく、検索パフォーマンスレポートのことだと思う。
全てのデータを表示できているわけではないのだが、ヘルプに掲載されている以上のことはお伝えできない。
URL パラメータはまだ機能しているか
【質問】
旧Search ConsoleのURL パラメータはまだ機能しているのか?
【回答】
機能している。
アイテム数の多い EC サイトの URL 制御
【質問】
ECサイトの一覧ページで、サイズや値段を絞り込むとパラメータ付きのURLが生成される。
商品点数が1000点以下だが、パラメータでURLが増えているので、数百万のURLがSearch Consoleで認識されている。
次のようにクロールバジェットを最適化するのが良いか?
①robots.txtでパラメータ付きURLへのクロールをdisallow
②canonicalで正規化
②だとGooglebotは数百万URLをクロールしてしまうので、①を実施しようとしているが問題ないか?
【回答】
①より②がいいのでは。
ファセットナビゲーションのベストプラクティスを参考にして欲しい。
新規サイトと、既存サイトでどのように設計するのかというのがある。既存サイトの場合は、クロールされる不要なページを増やさないことと、インデックス登録のシグナルを統合することの2つが重要になる。
パラメータツールを使って適切に設定して、クロールした上で、canonicalを使って正規化してください。
商品の構造化データに関する仕様確認
【質問】
商品の構造化データは、レビューをネストできるとあるが、1つの商品に複数のレビューがある場合、Product内でネストしたreviewについて、どのように対応するのがいいか?
1件のみ抜粋、複数件ともに設定が必要なのか?
【回答】
全て含めるようにしてください。
たとえば複数のレビューを含める場合は、ページにアクセスしたユーザーに表示されるレビューをすべて含める必要があります。
PDF も CWV の評価対象になるか
【質問】
Search Consoleのコアウェブバイタルレポートで、CLSとLCPについては「類似のURL」にPDFファイルが含まれていた、PDFファイルもコアウェブバイタルの評価対象になるのか?
【回答】
コアウェブバイタルは、CrUXレポートを元にしており、そのデータにはファイルタイプの制約はない。
注意点は、現時点でコアウェブバイタルが、ページエクスペリエンス ランキングシグナルに使われるのはモバイルのみ。
ご質問をする際は、データとしてのコアウェブバイタルなのか、ランキングシグナルとして質問されているのか、質問の際にしてくれると助かるとのこと。
埋め込みページはあるが「なし」と警告される
【質問】
Search Consoleで「コンテンツの不一致: 埋め込み動画なし」と表示されるページがある。
警告が出ているページ動画は表示されており、どのように対処すればいいのか教えて欲しい。
【回答】
頂いたURLを確認したところ、
サイトの構成はペアード AMP なのだが、ページネーションを実装しているページで、アノテーションに問題があるようだ。1ページ目は問題なかったが、2ページ目以降のcanonicalが1ページ目に向けられていた。構成を見直すことをおすすめする。
Article 構造化データ image プロパティ詳細
【質問】
AMPページに amp-imgタグで掲載していない画像を、Article構造データのimageプロパティに記述することに問題があるかどうか判断がつかないので質問する。
①「記事に直接属するマークアップされた画像のみを指定する必要があります」について。
記事に直接属するマークアップされた画像とは、Article構造データのimageプロパティに記述された画像という理解で問題ないか?
②「すべてのページに画像を少なくとも1つ含める必要があります」について。
「画像を少なくとも1つ含める」とは、Article構造データのimageプロパティのことなのか?それともamp-imgタグなのか?
【回答】
具体的なURLがなかったので、わからない点も多かった。
一般的には、AMPページも非AMPページも、同様の構造化データがマークアップされ、正規化されたページにある画像を使う。
①記事内にある画像を構造化データ内のimageプロパティに記述してください。
②Article構造データのimageプロパティのこと。
詳しくは構造化データのドキュメントをご覧ください。
Q&A と FAQ リッチリザルトレポートの変更
【質問】
Data anomalies in Search Consoleのヘルプページに、Q&AとFAQリッチリザルトのレポート対象が変更になったと掲載された。
- 変更前:root levelだけが検証対象
- 変更後:root levelの下も検証対象
root levelとは何か?
構造化データでマークアップしているのがroot levelなのか?
他の構造化データでネストしている場合は、以前は検証対象ではなかったということなのか?
Q&A and FAQ
Search Console now checks the validity of FAQ and Q&A structured data that is below the root entity level. Previously, we only checked entities at the root level. Therefore, you may see an increase in valid/warning/invalid FAQ and Q&A items to reflect an accurate count of root and nested entities that we found on your site.
【回答】
最上位レベルと下位レベルの概念は、書籍に関する構造化データが参考になる。
- 作品: 抽象的な概念としての書籍。具体的には、タイトル、著者、原著の言語などの作品に帰属するメタデータを指します。
- エディション: 実際に出版された書籍。具体的には、出版年、版の名称、国際標準図書番号(ISBN)などの刊行物に帰属するメタデータを指します。
「よくある質問」リッチリザルトの実装
【質問】
JSON-LDで実装し、リッチリザルトが表示されたが、HTMLタグを含んだ項目が表示されない。エスケープ処理はしている。
リッチリザルトテストツールでは正常に表示されているのだが、エスケープ処理をしても無視されることがあるのか?
【回答】
頂いたURLを確認した。
実際にリッチリザルトテストツールで正常に表示されなかったので、一度確認してください。
現在の状況は、検索結果にも表示されていないので仕様について確認して、チームにもフィードバックを送った。
ガイドライン違反リンクへの Google の対処
【質問】
ガイドライン違反したリンクに対しては無効化する方針で、ペナルティを与えることはないと、ジョン・ミューラー氏が発言している。
この説明では、人工リンクを購入して成果が出なかったとしてもマイナスにはならず、順位が上がればラッキーのような状況になってしまうのでは。もう少し詳しい説明が欲しい。
【回答】
誤解や解釈が難しい点もあるので、改めてジョンにも確認した。
実際にそういう意味だろうと思っていたことを確認できたので、解説する。
ショートアンサーとしては、リンクスパムを単に無効化しているだけで、スパム対策の対象になっていないということはない。自動の対策、手動の対策の対象となっているのでご安心ください。有料リンクを購入してバレなかった人が得をするような仕組みにはなっていないとのこと。
ジョンがTwitterで返信したのは、有料リンクを使って順位を上げようとしているサイトがあったとしても、Googleはランキング自体に対して有料リンクを無効化しているので、影響を受けることはないというニュアンス。手動対策を実際にするかどうかの話ではない。
多くの場合で、Googleはスパムリンクを無効化している。
ただ、そのようなリンクを買っているサイトが上位にある場合、うまくいっているように見えるかもしれないが、それ以外の要因(コンテンツの内容や関連性など)で優っている場合、上位に表示されているサイトもある。
手動対策されないのであれば、有料リンクを買ったもの勝ちになるのではということはないので安心してください。
AdSense の規約違反ではないのか
【質問】
テレビをスクリーンショットして違法アプロードしているブログが、AdSenseで広告収入を得ている。規約違反にならないのか?
【回答】
担当が違うので、ポリシーに違反しているかどうか言及しないが、違反しているとお考えであれば、AdSenseの報告窓口にご報告ください。
著作権者であれば、DMCAやサイト管理者に連絡をすることも考えてみては。
フィードバックは何のため?
【質問】
フィードバックをしても、改善されたこともないので、意味のない機能のように思われる。
【回答】
誤解がある。
フィードバックは何のためのためにあるのかというと、Google検索は、さまざまなチームが関わっており、皆様方から寄せられたフィードバックからデータを取得して、分析している。
個別に対応するというよりも、アルゴリズムに落とし込んで改善している。
膨大なフィードバックが送られてくるので、個別にお答えすることはできないが、優先順位をつけて改善を行なっている。送っていただかないと、どんな問題が発生指定しているか気が付きやすくなりので、何かお気づきの点があれば、お気軽に送ってくださいとのこと。
- Google 検索についてご満足いただけた点、ご不満な点
- 使いにくい機能、使用できなかった機能
- Google 検索に関する改善案
Google検索オフィスアワーに質問するには?
質問フォームから質問できます。
質問が多い場合は、翌月に持ち越されることもあります。
URLを非公開で質問したい場合、その旨記載すると、URLは公開されません。
次回は、2021年4月22日を予定しています。









ナレッジ